OllamaFX: Cómo ejecutar modelos IA en tu PC sin regalar tus datos
Desde la irrupción de ChatGPT y el desarrollo de modelos de IA como Gemini, Grok, Claude, etc., la IA se ha vuelto una herramienta de uso diario para todos. Sin embargo, esta comodidad tiene un precio invisible: tus datos y la privacidad. Cada consulta, archivo cargado o código pegado en estos servidores alimenta nubes de terceros en donde pierdes el control de los datos, para muchos profesionales, especialmente en áreas de desarrollo de software, sector financiero, legal entre muchos más, el manejo, la seguridad y privacidad de los datos es una actividad crítica no negociable.
La buena noticia es que ya no dependemos de una conexión a internet para tener potencia de cálculo inteligente. La tendencia actual es la IA Local, y aquí te explico cómo implementarla en tu propio equipo.
1. El motor de todo: Ollama
Para correr modelos de lenguaje (LLMs) localmente, la herramienta estándar de oro es Ollama. Es un motor eficiente que permite descargar y levantar modelos de IA generativa LLM (Large Language Model) potentes como Llama 3, Mistral o Phi-3 directamente en tu hardware. El beneficio es binario: si apagas el Wi-Fi, la IA sigue funcionando. Tus datos nunca salen de tu disco duro.
2. Tutorial: ¿Qué modelo de IA instalar según tu hardware?
La ejecución de modelos de IA Generativa como modelos LLM dependerá en gran medida de la capacidad y configuración de tu Hardware, así también como el objetivo y tamaño del modelo que deseas instalar, por ejemplo en la siguiente tabla vemos como un modelo Gemma de 2 Billones de parámetros puede ser usado en máquinas con capacidad de RAM de entre 4GB a 8GB.
| Capacidad de Hardware | Modelo Recomendado | Uso Ideal |
|---|---|---|
| 4GB VRAM / 8GB RAM | Phi-3 Mini o Gemma 2B | Tareas ligeras, resúmenes rápidos y laptops antiguas. |
| 8GB VRAM / 16GB RAM | Llama 3 (8B) o Mistral | El “punto dulce”. Programación, redacción y lógica compleja. |
| 12GB+ VRAM / 24GB+ RAM | Command R o Llama 3 (70B) | Análisis profundo de datos y tareas de razonamiento avanzado. |
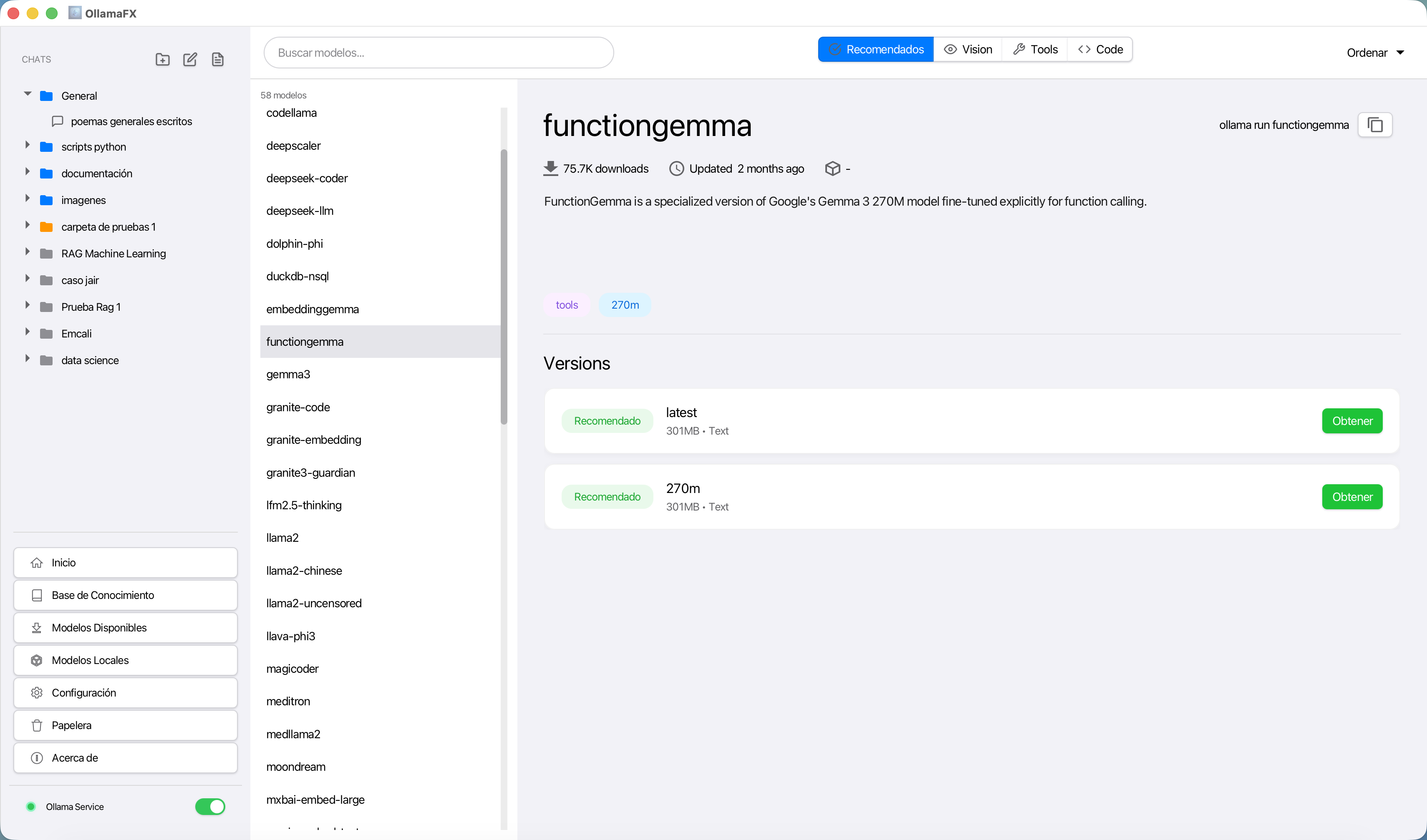
Para facilitar esta gestión, OllamaFX — un cliente nativo para Ollama Multiplataforma (Windows, Linux, MacOS) construido con JavaFX— integra un componente de galería de modelos disponibles para descargar en tu máquina.
Modelos LLM Disponibles
OllamaFX integra un motor que evalúa y clasifica los modelos según la capacidad de tu hardware y te dirá cuáles son recomendados, cuáles no deberías instalar y cuáles podrías instalar con precaución, esto permite que puedas usar modelos de IA generativa sin sacrificar o crashear tu computador.
3. Organización y flujo de trabajo: Más allá del chat
Una vez que tienes el modelo funcionando, el siguiente reto es el orden. La mayoría de las interfaces de chat son listas interminables de texto. En la versión 0.5.0 de OllamaFX se realizó una innovación importante, organiza tus chats por colores y por carpetas.
Crea carpetas y organiza tus chats: Capacidad de crear carpetas de chats, renombrar conversaciones y anclar (pin) aquellas que son críticas para tu día a día, clasifica tus carpetas por colores, mueve chats entre carpetas con solo arrastrar y soltar.
Contexto Persistente: No pierdas el hilo de tus investigaciones; la organización jerárquica permite separar proyectos de trabajo de consultas personales, además te permite poder usar presets configurados, ajusta los hiperparámetros del modelo según tu necesidad, puedes incluso ajustar y personalizar el System Prompting para que el modelo siempre siga tus instrucciones en cualquier interacción.
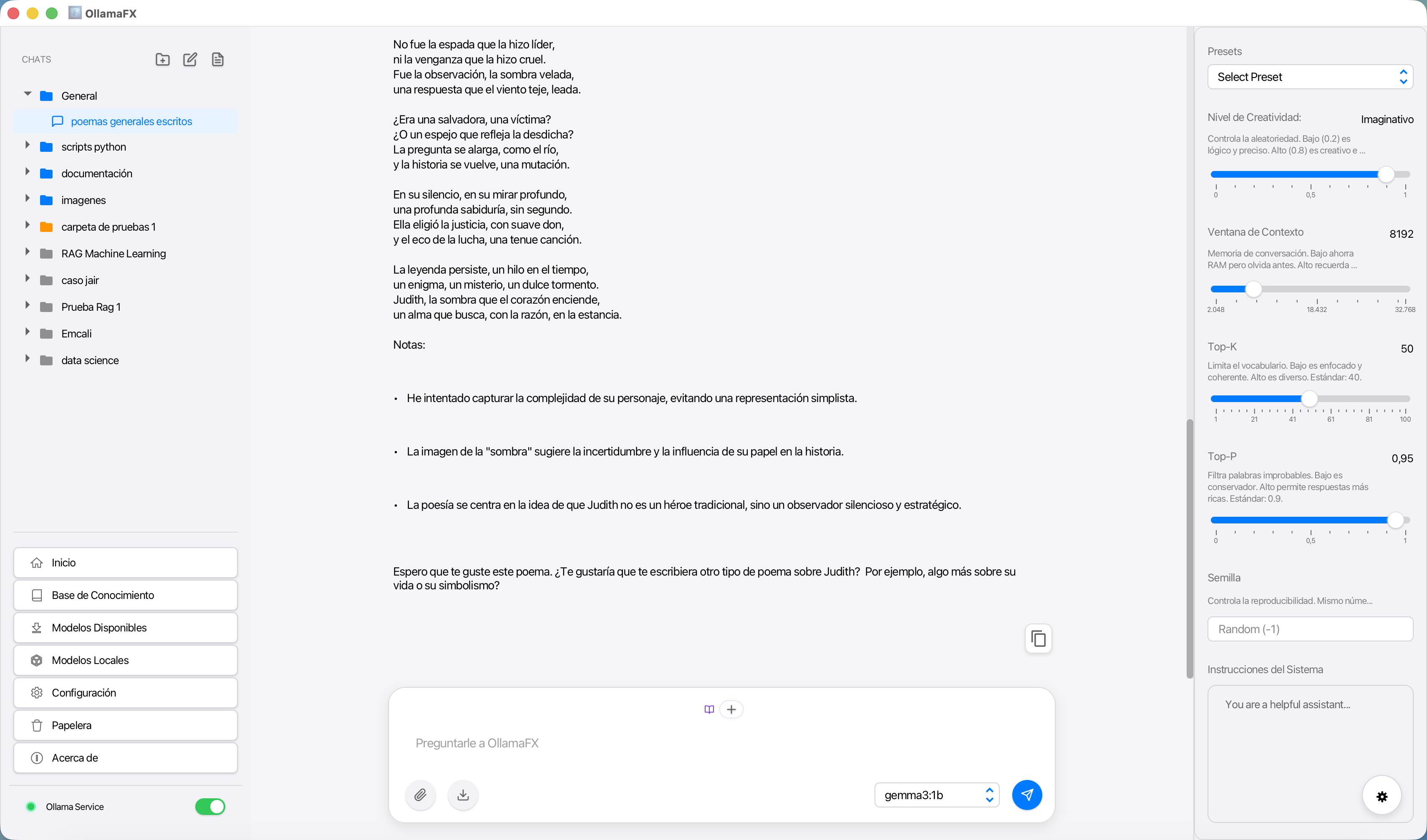
Chat con modelo LLM Ollama
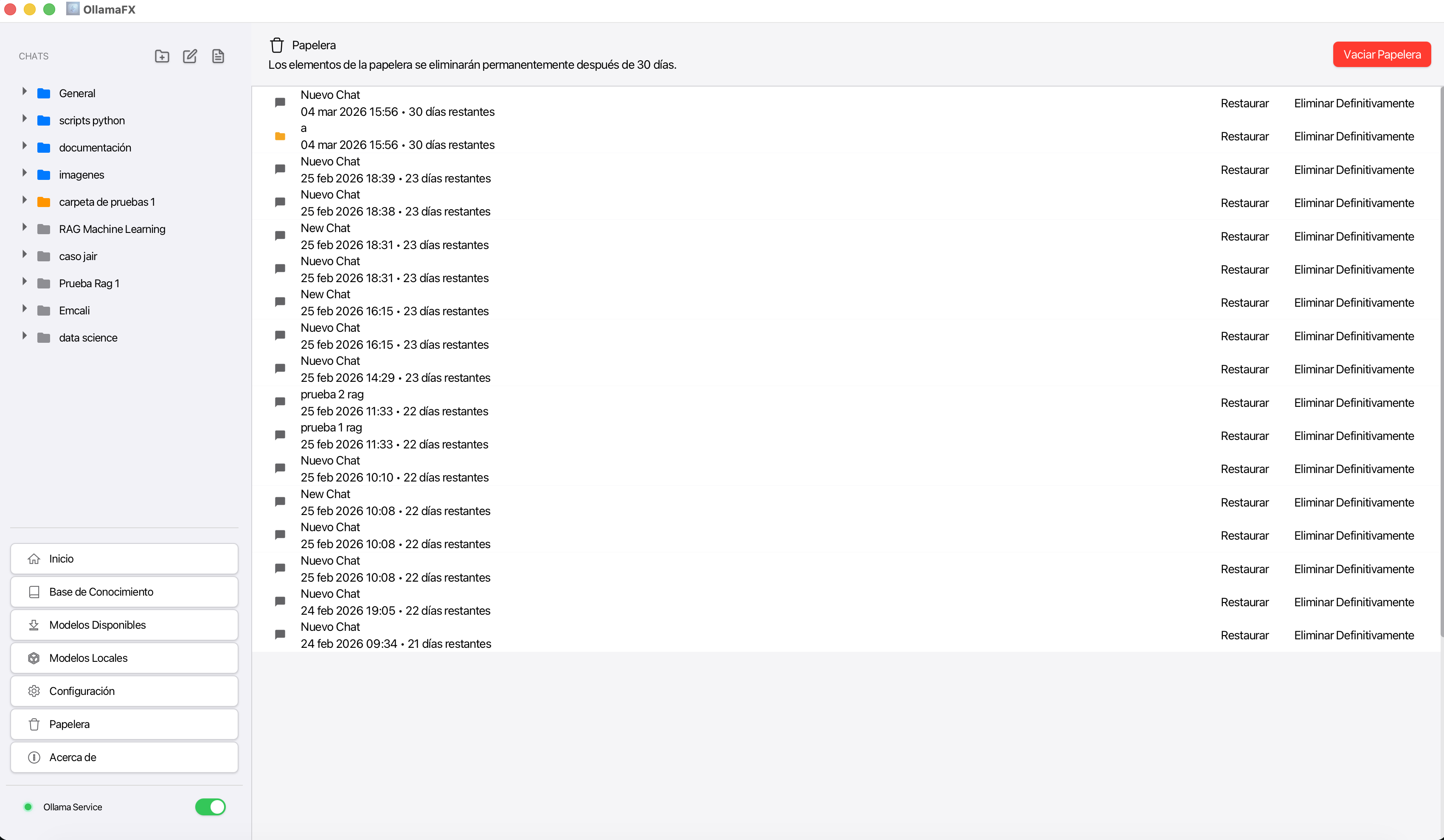
Papelera de reciclaje: una innovación fuerte en OllamaFX ha sido la incorporación de la papelera de reciclaje, puedes eliminar tus chats para limpiar tu workspace, pero este no se irá del todo, pues estará hasta 30 días en la papelera y durante ese tiempo podrás recuperarlo en la carpeta que existía previamente.
4. El “Santo Grial” de la Privacidad: RAG Local
La funcionalidad más buscada hoy es el RAG (Retrieval-Augmented Generation). Básicamente, es la capacidad de “inyectarle” tus propios documentos a la IA, en lugar de subir un PDF sensible a una web desconocida, puedes usar la función RAG de OllamaFX para cargar archivos .pdf o .txt localmente. El sistema vectoriza el documento en tu memoria y te permite hacer preguntas sobre él, así podrás obtener respuestas basadas en tus datos reales, con cero fugas de información.
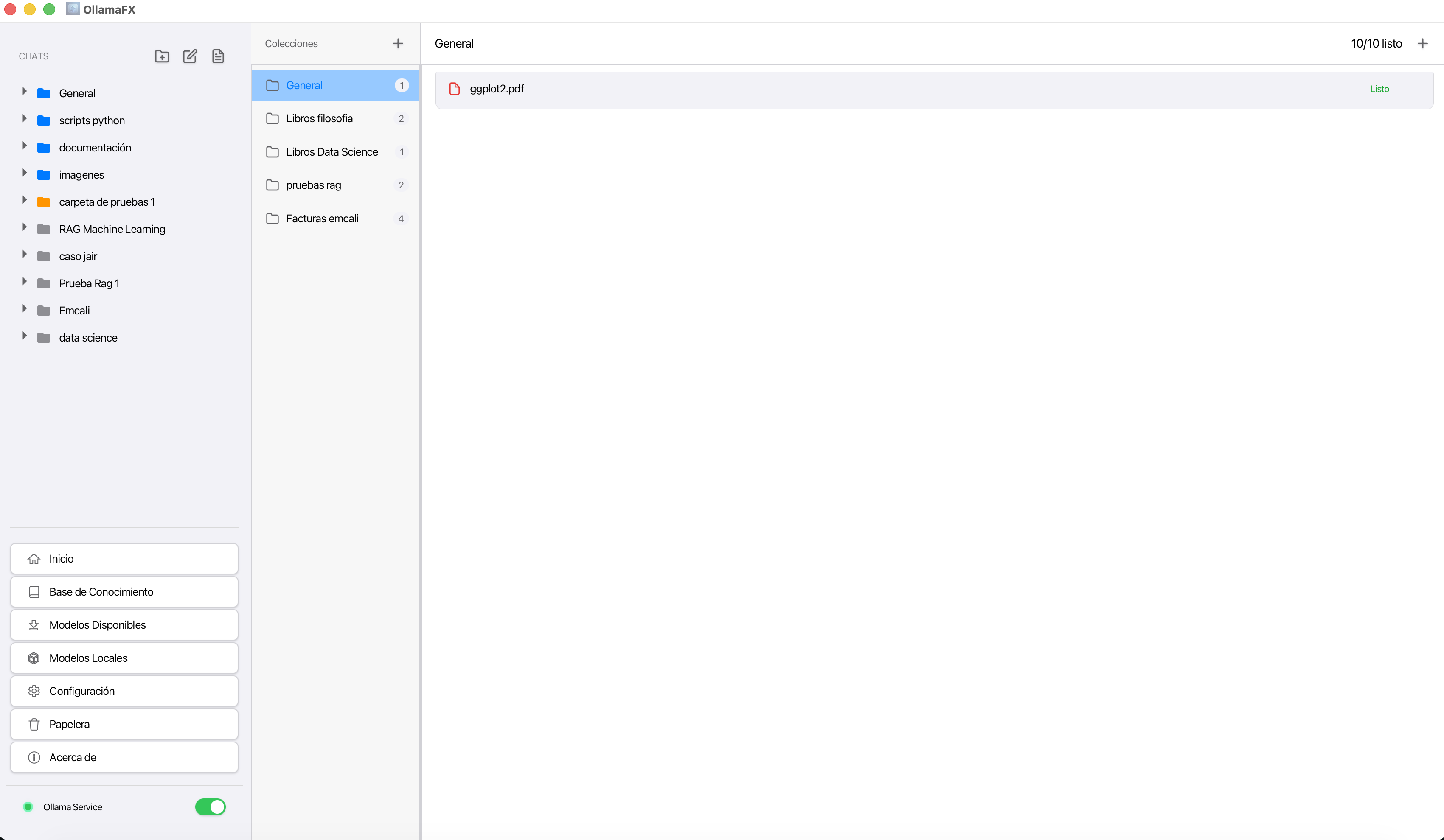
RAG para Ollama usando OllamaFX
Conclusión: Tu PC, tus modelos IA LLm y tus reglas
Instalar un LLM local no es solo una decisión técnica, es una declaración de principios sobre quién es el dueño de la información. Proyectos como OllamaFX nacen de esa necesidad: democratizar el acceso a la IA robusta, pero manteniendo la interfaz humana y el control total en manos del usuario.
Si quieres dar el paso hacia una IA privada, te invito a explorar el repositorio y probar cómo cambia tu flujo de trabajo cuando la nube ya no es un requisito. OllamaFX es un proyecto nuevo aún en desarrollo, estamos trabajando en seguir puliendo y mejorando la experiencia, este es un proyecto Open Source el cual puedes usar de manera libre, si eres desarrollador y puedes apoyar el proyecto testeando la aplicación, solucionando bugs, implementando nuevas mejoras, ayudando en la documentación etc. eres bienvenido, o si eres un usuario final y tienes ideas, comentarios todos son bienvenidos.
- Web del Proyecto: https://fredericksalazar.wordpress.com/proyectos/ollamafx/
- Código y Descargas: GitHub de OllamaFX