Machine Learning en el PIB Per Cápita: Análisis con KMeans (Parte 1)
Con el objetivo de poner en práctica mis conocimientos sobre Machine Learning, comparto este proyecto en el que he estado trabajando. El objetivo principal es aplicar modelos de Machine Learning al dataset de PIB Per Cápita que publiqué en Kaggle hace un tiempo.
Aplicación de Machine Learning No Supervisado
Nos enfocaremos en dos áreas. En esta primera parte, abordaremos un modelo de Machine Learning no supervisado. Recordemos que este tipo de modelos nos ayuda a descubrir patrones en los datos. Aplicaremos un modelo de clusterización llamado KMeans, el cual se especializa en agrupar los datos según sus características, creando grupos que sean muy diferentes entre sí. Dentro de cada grupo, los datos deben ser lo más similares posibles.
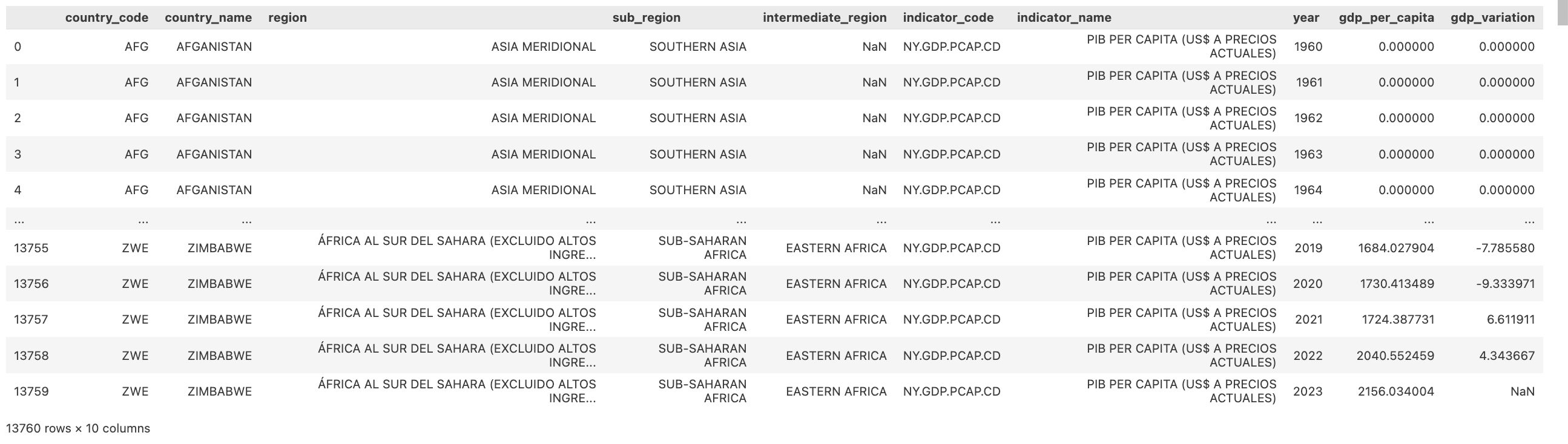
¡Ahora manos a la obra! El set de datos que vamos a usar tiene la siguiente estructura:
No me enfocaré aquí en enseñar el código para aplicar KMeans, sino que compartiré los resultados obtenidos del análisis, para quienes deseen explorar el código desarrollado les comparto el link a la notebook en Kaggle. https://www.kaggle.com/code/fredericksalazar/machine-learning-applied-to-gdp-per-capita
Distribución del PIB Per Cápita
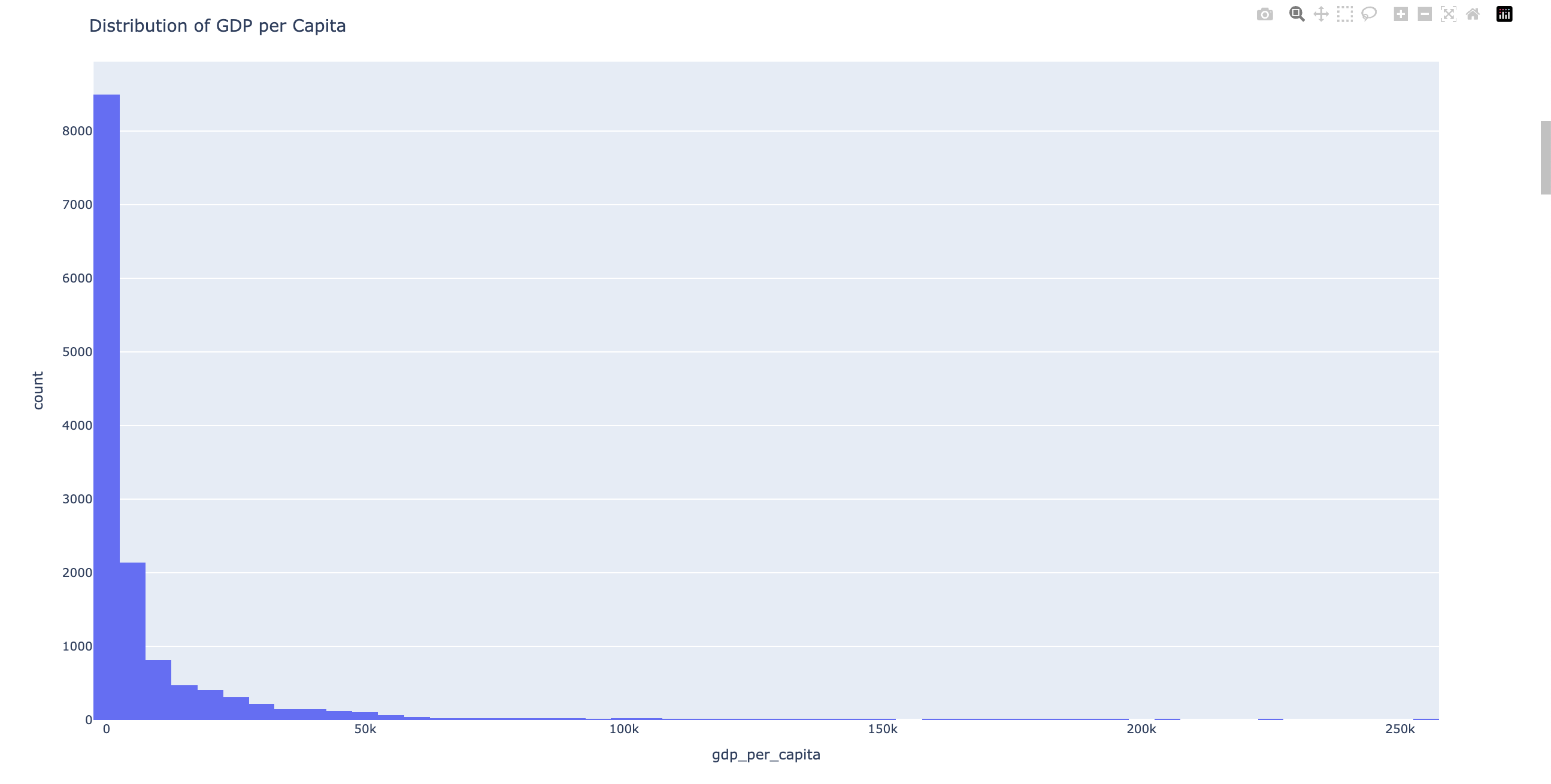
Si analizamos la distribución del PIB per cápita del dataset, podemos observar una gráfica en la que existe un grupo de países con un PIB per cápita superior a 100.000 dólares. Sin embargo, la gran mayoría de los países del mundo se encuentra entre 0 y 2.500 dólares anuales.
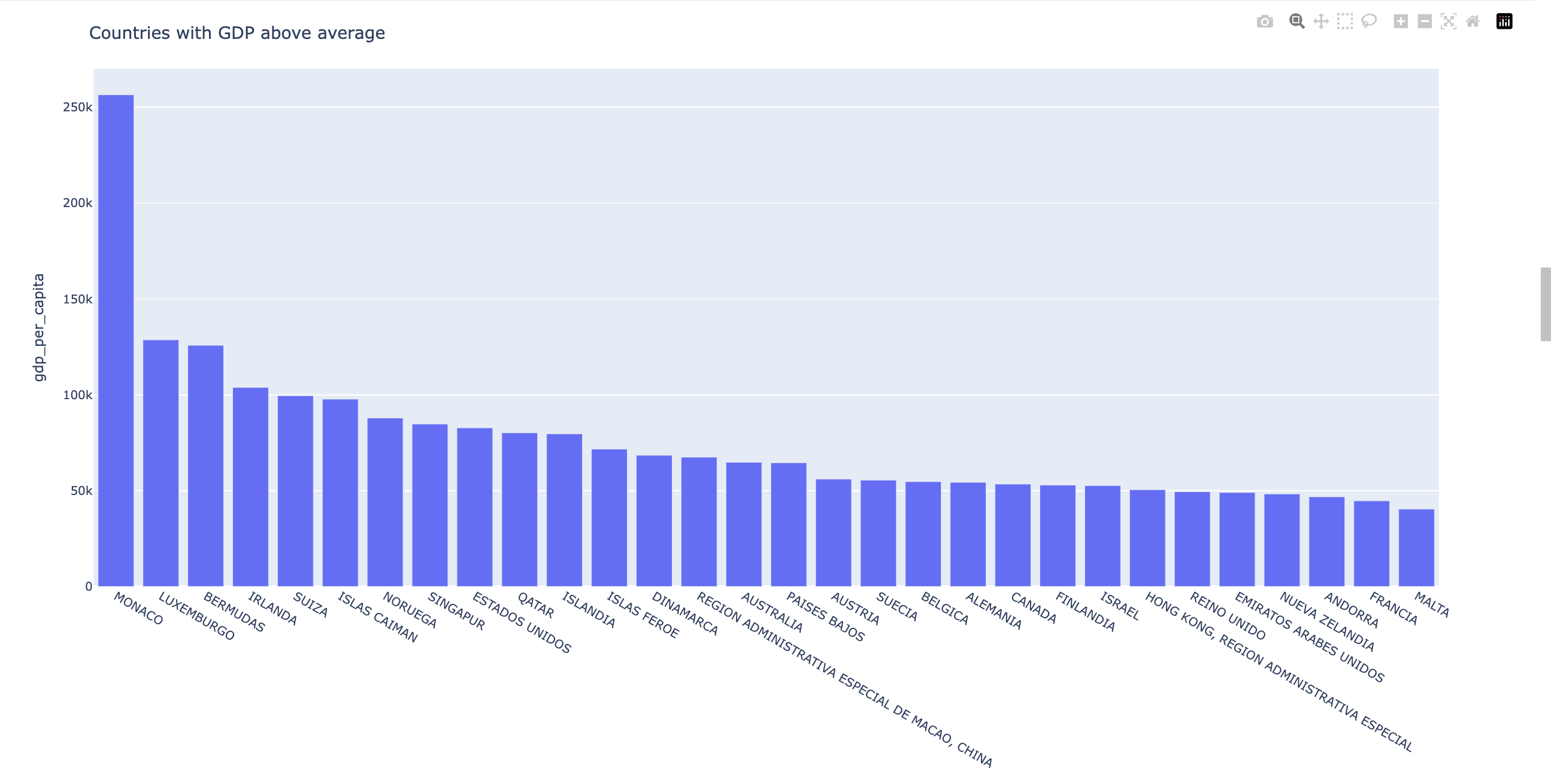
Países mas Ricos del 2023
Al enfocarnos en el año 2023, encontramos que la media del PIB per cápita se sitúa en 20.000 dólares anuales. A partir de esto, identificamos los 30 países cuyo PIB supera la media mundial y generamos la siguiente gráfica.
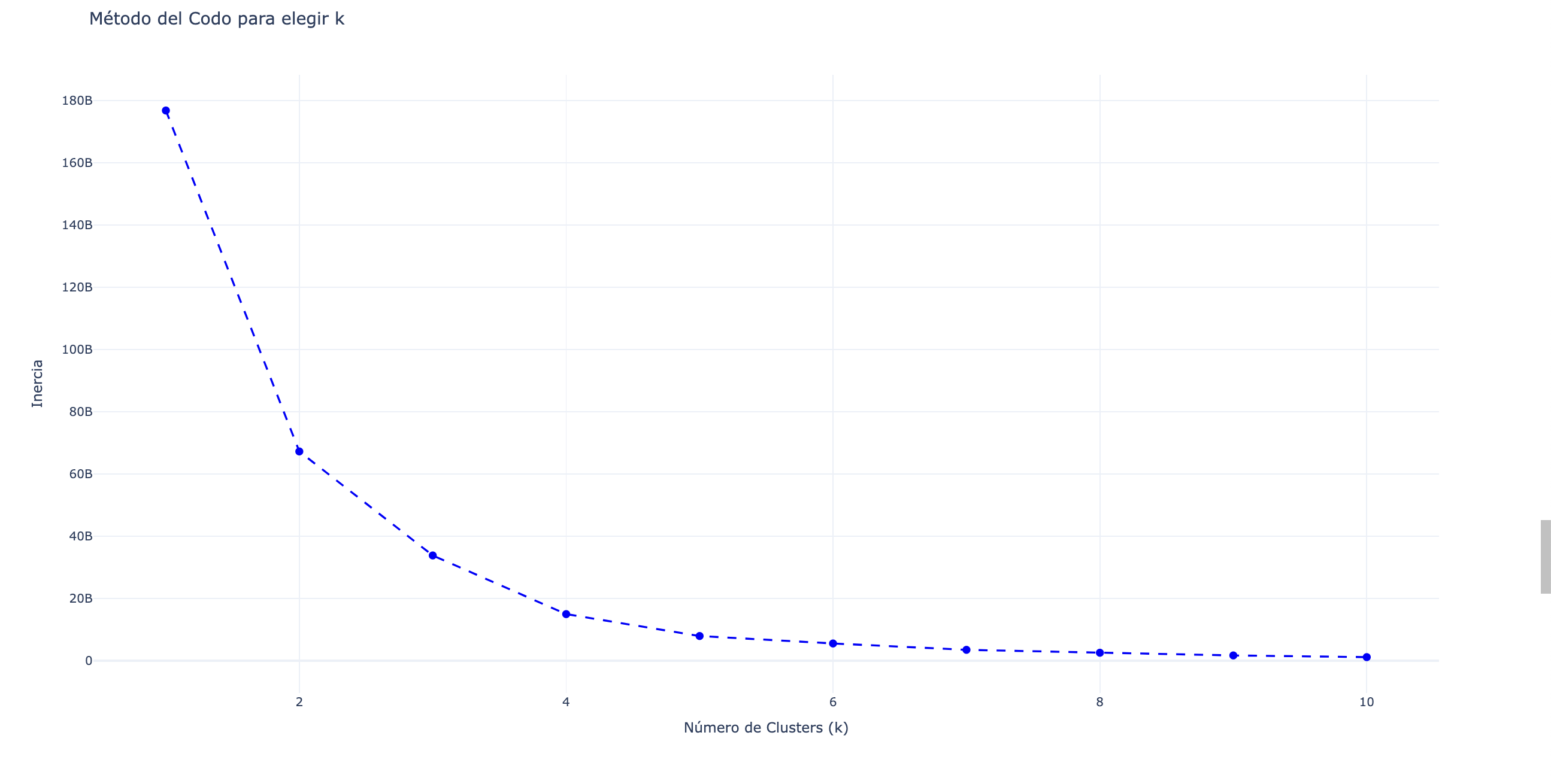
Clusterización del dataset usando KMeans
El primer paso es identificar la cantidad óptima de clusters para separar los datos. Para esto, utilizamos el método del codo. En la siguiente gráfica, realizamos un ciclo de clusterización de 0 a 10 clusters. El punto clave es identificar en la curva el momento en que los clusters se estabilizan o forman un “codo”. En este caso, observamos claramente que 2 es el número de clusters más indicado para nuestro dataset.
Experimentamos con 3 clusters, lo que generó un grupo con un solo país. Esto nos confirma que la segmentación correcta es con dos clusters. Ahora, veamos la composición de cada grupo.
Países del grupo 0
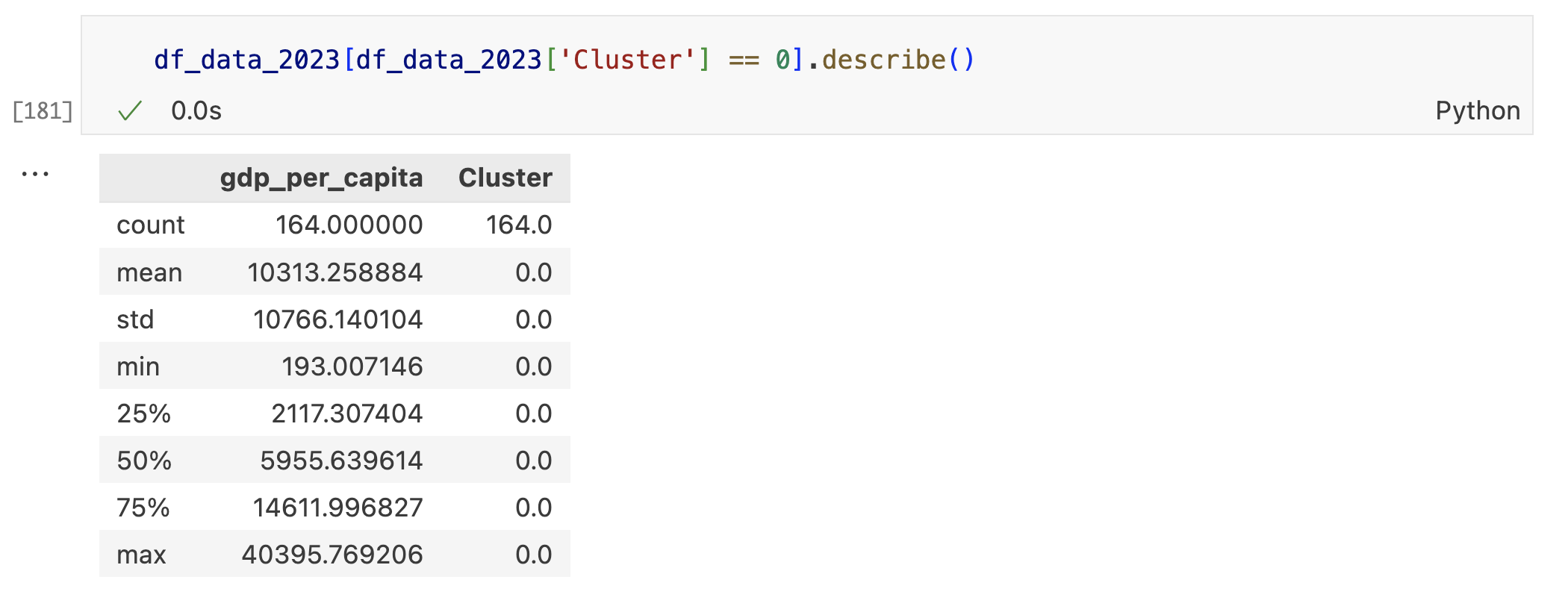
Este grupo está compuesto por 164 países, con una media de PIB per cápita de 10.313 dólares. Además, el PIB per cápita máximo dentro de este grupo es de 40.395 dólares.
Países del grupo 1
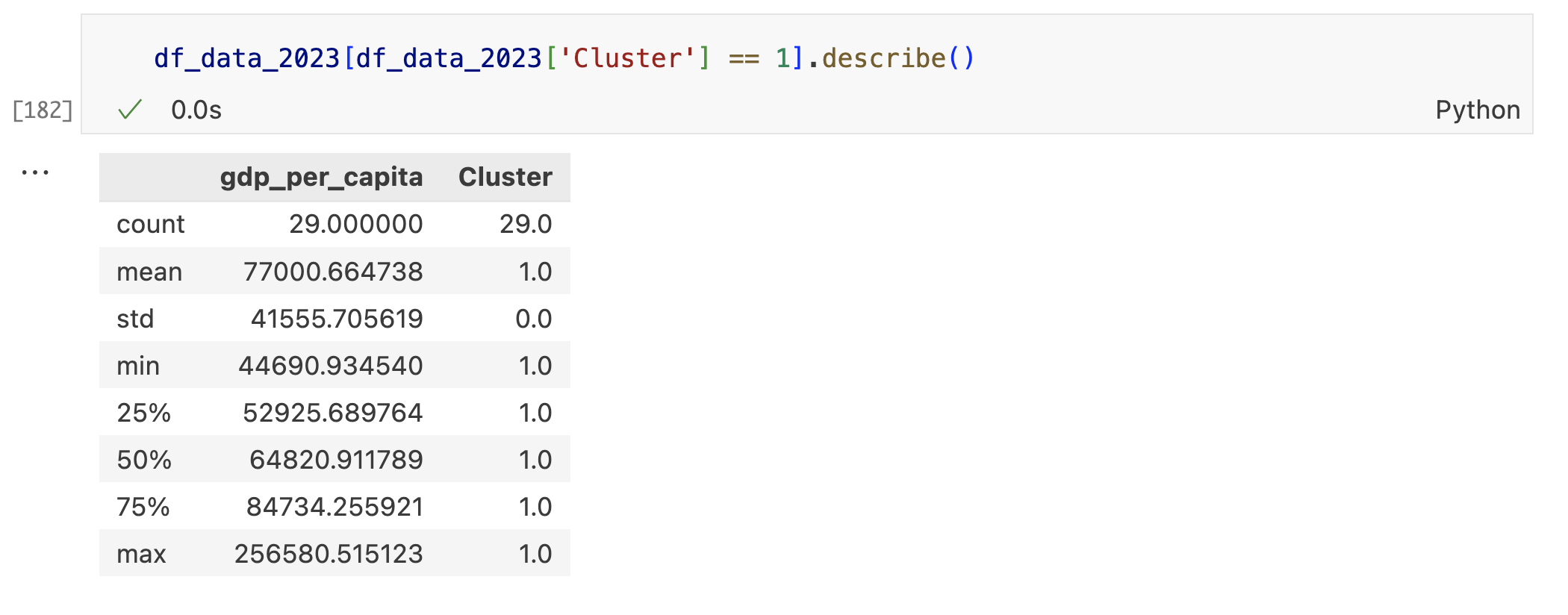
Este grupo está conformado por 29 países, con una media de PIB per cápita de 77.000 dólares. Su PIB mínimo es de 44.690 dólares y el máximo alcanza los 256.580 dólares. Claramente, aquí se agrupan los países más ricos del mundo.
Visualización del PIB Per Capita según los Clusters
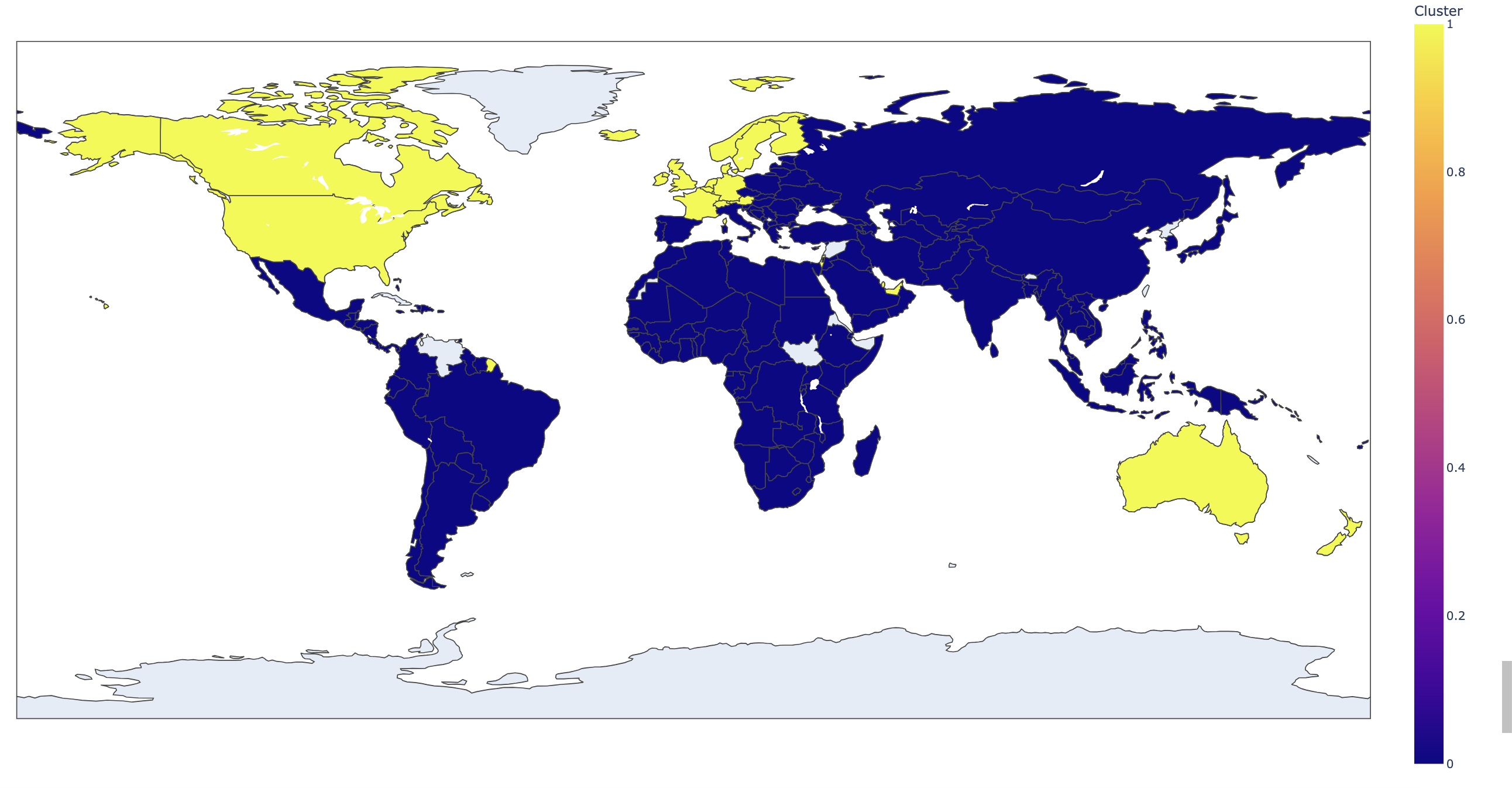
En el siguiente mapa, ubicamos los países según su cluster:
- En amarillo, los 29 países con los PIB per cápita más altos del mundo.
- En azul, los demás países, cuyos PIB per cápita no alcanzan para ser parte del grupo de los más ricos.
Conclusión y Próximos Pasos
Este análisis nos permitió segmentar los países según su nivel de riqueza usando Machine Learning. En la segunda parte, nos enfocaremos en desarrollar un modelo de predicción del PIB per cápita basado en datos históricos.
¿Qué opinas de este ejercicio? ¡Te leo en los comentarios!