Ciclo de vida de la Ingeniería de datos
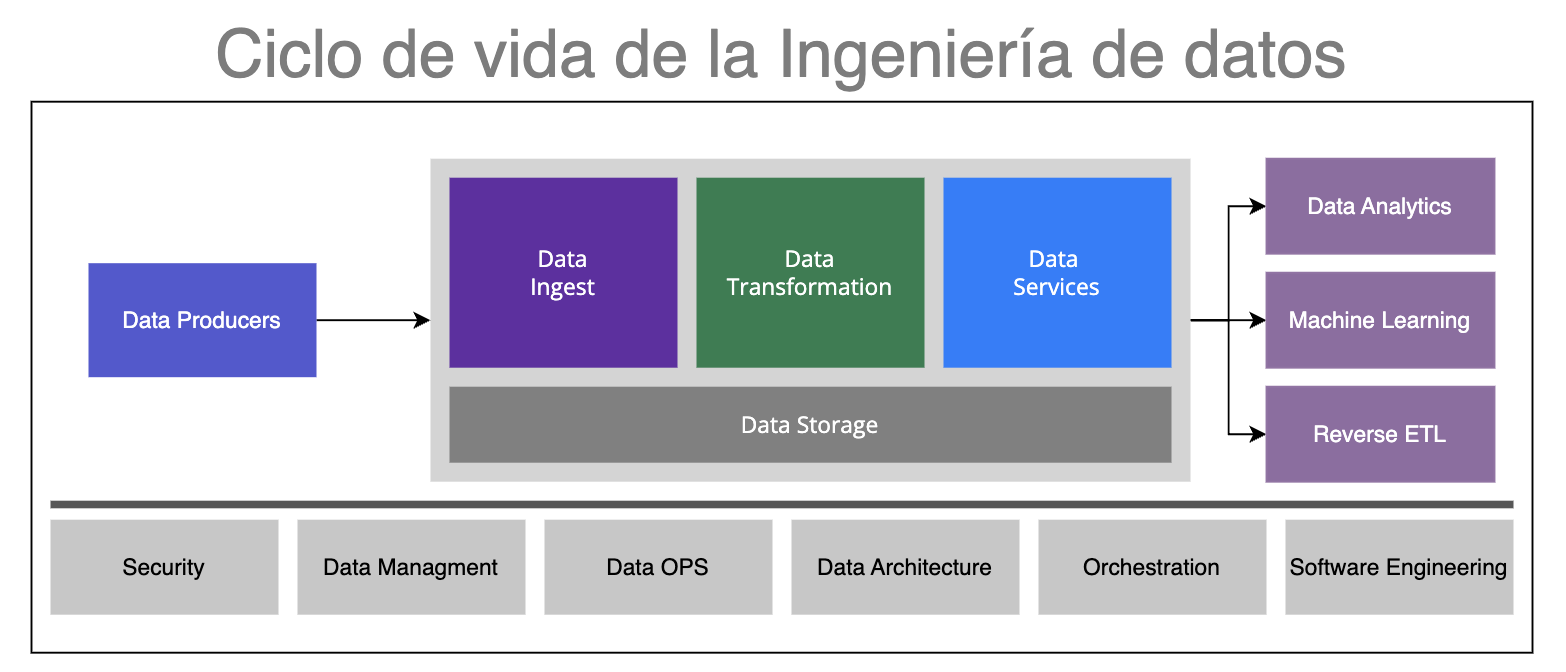
Los datos son la unidad básica de la información, todo experto en datos debería lograr de una manera abstracta, ver los datos como átomos vivientes que fluyen a través de las organizaciones, alimentando procesos, personas y tecnologías. Según Joise, el ciclo de vida de la ingeniería de datos, es un subconjunto del ciclo de vida del dato, por eso es tan importante comprender el ciclo de vida de los datos de una organización, para usarlos de manera estratégica, no solo para la toma de decisiones sino para optimizar procesos empresariales ayudando a aumentar la productividad y eficiencia organizacional. A continuación explicaré de manera resumida cada una de las fases , en post siguientes iremos estudiando cada una de manera detallada.
En su libro Fundamentals of Data Engineering de Joise reise & Matt Housley [1] definen el ciclo de vida de la ingeniería de datos como:
Conjunto de etapas relacionadas que convierten los datos en bruto en un producto final útil, listo para el consumo de analistas, científicos de datos, ingenieros de aprendizaje automático y otros.
En este ciclo de vida se encuentran las siguientes fases:
- Generación de datos
- Almacenamiento de datos
- Ingesta de datos
- Transformación de datos
- Servicios de datos
Data Producers: La creación de nuevos datos en las organizaciones es una de las actividades principales en todo tipo de organizaciones, desde nuevos registros en una base de datos, la captación de datos de sensores IoT, la creación de archivos excel, csv, word, etc. pasando por logs de sistemas ERP, RRHH, CRM y un gran abanico de opciones, todo todo absolutamente todo son datos e identificar su origen, tipología, frecuencia etc es fundamental en la gestión de información empresarial.
Data Storage: el almacenamiento de datos hoy es mucho mas barato y con capacidad que hace un par de décadas, bases de datos relacionales, NoSQL, Data Lakes, sistemas en nube, on-premise, por lo general las organizaciones usan persistencia poliglota en la cual usan varias tecnologías de almacenamiento de datos, seleccionar una buena arquitectura de datos, deberá estar condicionado por un estudio detallado de necesidades y requerimientos empresariales, que van desde la frecuencia de acceso, replicación, encriptación, seguridad entre muchos otros aspectos. Esta capa es transversal en todo el ciclo de vida dado que en cada una de las fases requerimos persistir o leer datos.
Data Ingest: La ingesta de datos es una de las actividades mas importantes para el uso de datos como activos de valor analítico, una de las mas criticas del ciclo y en la que generalmente se presenta mayor cantidad de problemas, una gestión eficiente requiere de una arquitectura, planificación, monitoreo y mantenimiento eficientes, el uso de herramientas adecuadas asegura que los datos fluyan desde los orígenes hacia la organización de manera segura y confiable. La ingesta de datos ayuda a cumplir con uno de los pilares de la gestión de la información, la disponibilidad, que los datos estén cuando se necesitan y donde se necesitan, para esto debemos entender muy bien la frecuencia de los datos y la necesidad de la organización para saber si ingestar en tiempo real o en batch, ahondaremos mas adelante.
Data Transformation: Momento donde los datos inician su fase de enriquecimiento, muchas transformaciones pueden ser aplicadas con muchos objetivos, mejorar la calidad, crear nuevos datos, agregar nuevos datos etc. Transformar los datos crudos en datos con valor analítico nos servirá para que puedan ser usados en modelos de Machine Learning, Bussines Intelligence, Inteligencia artificial, análisis de datos o incluso el cumplimiento de normas legales y entrega de información a organizaciones gubernamentales según sea el caso.
Data Services: Si los datos ingestados, transformados y almacenados no son usados dentro de la organización entonces estos son datos muertos, datos sin valor estratégico y una perdida de oportunidad y dinero, esta fase es muy importante, el uso de datos como servicio potenciará a la organización, por ejemplo: la creación de dashboards para monitorear diferentes KPIs y OKRs, el uso de Operational Analytics, People Analytics, Customer Analytics, la creación de modelos de machine learning, el entrenamiento de modelos de IA etc. los datos deben tener un propósito para su uso, de lo contrario se convierten en lodo y no ayudan para nada a la organización. Un caso de uso es el ETL inverso, casos donde tomamos datos desde orígenes se transforman y son devueltos a sistemas origen, no es muy común y se considera una mala practica pero son cada vez mas usados de manera pragmática y eficiente.
Para finalizar vemos que de manera transversal los datos son gestionado por áreas como:
- Seguridad: se deben tener políticas, procedimientos y técnicas que aseguren los datos en su ciclo de vida a niveles de control de acceso, encriptación, gestión de datos personales, anonimización etc.
- Data managment: La gestión de los datos a nivel empresarial requieren de una visión estratégica de los mismos que implementen gobierno del dato, modelado de los datos, asegurar la integridad e interoperabilidad de los datos, la ética y privacidad en el uso de los dato y mas importante la confianza y seguridad en la toma de decisiones basadas en datos.
- Data OPS: La ingeniería de datos toma prestados muchos conceptos de la ingeniería del software para la gestión de proyectos de datos, aquí entra Data OPS que intenta mejorar la cultura organizacional implementando las mejores practicas para la gestión del ciclo, automatizando tareas, entregando valor en ciclos cortos y ayudando a la organización a cumplir sus objetivos con activos de datos.
- Data Architecture: Uno de los aspectos mas importantes en la gestión de información empresarial y donde la mayoría de organizaciones suelen fallar, es integrar los objetivos del negocios y la gestión de los datos, aquí es donde la arquitectura tiene un rol fundamental, pues integra la visión de negocio, la arquitectura empresarial y la arquitectura de datos con el objetivo de alinear las necesidades empresariales a las actividades propias de la ingeniería, con el único objetivo que los datos tengan valor estratégico y aporten a los objetivos organizacionales.
- Data Orchestration: La gestión de datos requiere que las ingestas sean orquestadas de manera tal que aseguren la maxima disponibilidad, esto requiere de sistemas que coordinen de manera ordenada y definida las diferentes tareas requeridas teniendo en cuenta aspectos como gestión de fallos, disponibilidad de información, notificación de resultados, monitoreo de actividades etc.
- Software Engineering: Podríamos decir que la Ingeniería de datos es una hija de la Ingeniería del software, todo ingeniero de datos debería tener conocimientos al menos básicos de ingeniería de software, conocer al menos Python, Java y SQL pues muchas de sus tareas y actividades harán uso de herramientas técnicas y conceptos del desarrollo de software, temas como streaming de datos, gestión de batch, pipelines as code, infrastructure as code, cloud computing etc son campos de conocimiento frecuentes en la ingenieria de datos moderna.
Aquí abordamos un poco de manera resumida el ciclo de vida de la Ingeniería de datos como aspecto fundamental de la gestión de datos empresariales, un conocimiento general de este ciclo de vida en la organización ayudará a todos los niveles (Operativo, Táctico y estratégico) a alinear de manera efectiva los objetivos de la organización con la generación de activos de datos para la toma de decisiones, espero les sea de ayuda y puedan incorporar cada uno de los conceptos aquí tratados en su organización y conocimiento personal.
Referencia bibliográfica
[1] Reis, J., & Housley, M. (2022). Fundamentals of Data Engineering. O’Reilly Media.